

Today I finally was able to download and run largest Qwen 3.5 model. I downloaded the smallest quant even if a bit bigger probably would fit too, but I want to run also few smaller models at the same time, so 107GB for UD-IQ1_M is the biggest I was able to spare.
I downloaded and was able to run it with llama.cpp with the following command:
./llama-server \ -hf unsloth/Qwen3.5-397B-A17B-GGUF:UD-IQ1_M\ --ctx-size 32000 \ --no-warmup \ --no-mmap \ --flash-attn on \ --n-gpu-layers 1 \ --host 0.0.0.0\ --port $1 \ --direct-io \ --jinja --chat-template-file /data/apps/vllm/qwen3_nonthinking.jinja
My intention was to test it with nanobot to see if this will be capable agent for my AI assistant.
For example I asked how is today’s weather:
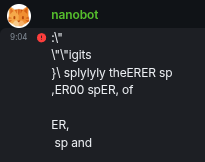
ER +,att experimentally,ER
def sp
ER�ER
sp,,ER.-sER
the
\”
Hausti1 in
ER,
, sp sp “ER\”).
spERomit
I checked few other prompts and it was like that for all of them.
Just to check if this not the problem with the model, or llama.cpp or combination of parameters passes to it, I called the API directly:
curl http://localhost:$1/v1/chat/completions \
-H "Content-Type: application/json" \
-d "{\
\"messages\": \
[ \
{ \
\"role\": \"user\", \
\"content\": \
[ \
{ \
\"type\": \"text\", \
\"text\": \"Hello!\" \
} \
] \
} \
], \
\"temperature\":0.7, \
\"top_p\":0.80, \
\"min_p\":0.0, \
\"presence_penalty\":1.5, \
\"repetition_penalty\":1.0, \
\"top_k\": 20, \
\"enable_thinking\": false \
}"
{"choices":[{"finish_reason":"stop","index":0,"message":{"role":"assistant","content":"Hello! How can I help you today?"}}],"created":1774885465,"model":"unsloth/Qwen3.5-397B-A17B-GGUF:UD-IQ1_M","system_fingerprint":"b8522-9c600bcd4","object":"chat.completion","usage":{"completion_tokens":10,"prompt_tokens":14,"total_tokens":24,"prompt_tokens_details":{"cached_tokens":0}},"id":"chatcmpl-h8de9riukfOoLWE6ctt1KltwxXRUl06N","timings":{"cache_n":0,"prompt_n":14,"prompt_ms":1258.476,"prompt_per_token_ms":89.105428571428572,"prompt_per_second":11.30620888922939,"predicted_n":10,"predicted_ms":340.439,"predicted_per_token_ms":89.0439,"predicted_per_second":109.373837897538174}}
So I guess it just has the problem with longer texts at this level of quantizations.
I guess I wont be switching to bigger models for now.