


Few years back I was writing, this time for myself, yet another one CRUD API. Goal was to enable to control my heat pump and few other devices from my own phone. I wanted to regulate temperature inside my home, or hot water, open close the main gate and similar operations. Me and my family still are using that one (though I am the only one aware that some API is somewhere 🙂 ). The issue I found myself in is that, I already did that! Multiple times!
- Oauth Authorization and Authentication
- Data validation
- Data base schema
- Entity Framework configuration
- HTTP endpoints
- Filtering of data (
list.Where
Nothing new there! It was boring but I needed this done!
Why there is no ready to use solution for that?!
And you may say right now ‘there is! just use X and Y! Or Z and ABC’ and this may be true. But at the same time my API had other functionality like connecting via MODBUS or proxying HTTP calls to other small WWW servers hosted on Raspberry Pis on other places. It could be possible in those other solutions but according to my experience instead of fighting with code (to force it to do what you want) you fighting with configuration (to force it to do what you want). And from my experience doing both, through out my career, I prefer fighting with code – at least you can debug the damn thing!
Seeds of Auto development
What I needed to have solution to create dynamic API simply by instructing system:
I need an API to serve following JSON structure:
{ "id":"snsr_id", "name": "sensor", "status": "active", "temperature": 23.32, "history": [ { "dateTime": "2023-10-21T10:32:08+2:00", "temperature": 13.53 } ] }
And the system would figure out us much as possible:
- JSON schema for following JSON
- entities that are needed inside the database
- Entity Framework configuration for entities
- API Dtos
- Validation of API data
- API endpoints
Seems complicated? Yes. But is it really? When you think about as a software developer you had task like that. Not once. Not twice. Not even few. This is what you are doing basically every day. Everything is now APIs and data shuffled from one API to another. From one database to another database. From one data structure (JSON) mapped to another (Dto, DAL data, db schema).
Yes, details of implementation varies from system to system. But the core principle does not.
Yes, usually software development is from database scheme up, via data access layer to the API and JSON structure. But reversing an order would not be that hard right?
Do that when this – AKA extensibility
On the other hand I would need this system to be extensible and run specific piece of code at specific events (i.e. modification of another data, messages triggered by agents running on machines, cron expressions and etc). This could be possible again by simply:
Give me API endpoint /custom/notify-me and run this custom code there:
new HttpClient().Post("/another-api/some-endpoint", "{ \"message\": \"hello!\" }");
I am mostly .NET developer so extensibility in C# would be nice (and easy to implement, at least for me since I will be developing that in C# any way). But why not make it possible to write such extensions in Python or JavaScript too?!
So it should be possible. Of course again devil is in the details and the end result that make it possible can be ugly with actual code structure and list of requirements that code need to adhere to, to be valid and runnable. But it may be not that bad.
I won’t know without even trying! So why not try it? The worst that can happen is that I fail but will learn bunch of new things in the process, that may be of use in my actual day to day job, or I will be able to talk about during my interviews. The best that can happen is that I actually build it, it will be nice and it will be something that I can use for my own purposes and maybe it will be used by other people too!
Now you may thing: ok but why? You may built custom tailored API in a week. This will take much more time!
Ok but why not? There are few interesting points to thing about: i.e. how to structure the actual code that will serve this dynamic API? Does ASP.NET core allows even for dynamically configured API endpoints? (Actually I knew already that it does). How that code and architecture of such system would be structured? (Actually I knew that one also, and wanted to try with source generators for a while now). How to make such system extensible? Well, any extensible system is either bunch of interfaces or dynamically loaded code. (Which I did not knew but few solution that I saw like in Jellyfin and Nextcloud seemed terrible).
I asked somewhat similar question on Hacker News and got answer: “why not!”.
And this is I think the most important answer. Why not? If you can try and fail and learn something in the process why not? If you will be afraid of failing, you will never try. You will never learn. You will never grow as professional and as a person.
Also I had really bad, uninteresting project at the time so doing something actually demanding and interesting on the side as Open Source would be good idea to think about something else. I was really in a bad place at that time, lost my confidence, the trust in my own skills. Doing something demanding and complicated was my own way of proving to myself that I can do it actually. And I can do it *better*. Or a way of self applied therapy.
Ok. But how?
By a lot of code! Obviously! Beside that:
- JSON schemas
- Code generation
- Dynamically configured API endpoints
- dynamic pieces of logic run by Flows
I already new how this works. Do some experiments, did some projects that were using some of those ideas. In example in one project JSON Schemas were used test Frontend for correctness its internal data structure – data structure had to adhere to schema. In other project I created dynamically configured API for testing of other components. In example instead of testing your component with external API you would configure your mocked API to have the same endpoints as external one and serve responses that you need.
Also I was previously playing with tools that generate code from JSON Schemas or JSON Schemas from code. Or generating JSON based on JSON schema or JSON Schema from JSON.
Also platforms that could be configured to make data of your choice editable and run processes that you need and want have some variant of resource query language. I did not plan to implement something like that in the beginning but it felt obviously missing when I get to implementation of GET collection endpoints. And I already had professional experience working on one already too and it touches manipulation of Linq expressions trees, dynamic code generation using that – which I used professionally and personally in my other open source project Delegates Factory.
So it seemed like know almost all the blocks already. All needed to be done is to just join them together!
Ok. But seriously how?!
Detailed architecture is discussed in other page, but from the grand view of things, Hamster Wheel Platform consists mostly from the API and its extensions (dynamically build or specifically tailored to do specific things – Flows or Static Pages i.e.).
API is heavily modified ASP.NET core API host. It have several parts that are pluggable and configurable:
- authorization and authentication
- list of endpoints
- monitoring and logging
- current user data
- DI services
- data transactions
- data validation
- data mapping and links generation
- internal message exchange
- configuration
- serialization of data
- data templates
All of those interfaces are implemented by extensions dynamically generated during extending of API based on JSON schema files provided to the system via special administration endpoints.
In example when you start the platform for first time there is only two endpoints available:
- /install/flow – configures and install core extension that is necessary for system to be used
- /status – return server status
When you provide necessary data for the first one which consists of:
- your user data (name, email etc)
- Oidc Provider configuration
you installs Core extension that consist of several entities:
- Api Tokens – users API tokens for programmatic access to API
- Extensions – list of extensions installed in the system
- Flows – list of flows installed in the system
- OidcProviders – list of Oidc Providers configured in the system that can be used for user authentication
- Scopes – list of scopes for granular access to the API, if necessary, be default only one is defined
- Templates – templates for use in various parts of the system: flows, API, files
- Users – list of users authorized to use system
Also Core extension installs few flows:
- add extensions generated from JSON files or from global repository
- post installation flows
- update and remove extension flows
The installation process of Core extension is Flow on its own. Just defined a bit differently and placed in Platform API host by default.
The flow of such installation process is following:
- system creates temporary
builddirectory - places necessary files in that directory:
- .NET Project file and other .NET build files
- Entities JSON Schemas files
- Flows JSON files
- Core extension code files
- runs .NET build process in that directory
- runs Entity Framework migration commands in that directory
- runs .NET publish command
- this also copies all the build artifacts to the
extensiondirectory for the host load later
- this also copies all the build artifacts to the
- Adds new extension to the system
- necessary data is added (user data, API token if asked for, Oidc provider data, extension data etc)
- extension post install flow is triggered
- and this flow adds extension flows to the system
- adds extension templates to the system
- adds system templates to the system (i.e. Core extension files used for installation)
- extension is marked active
All the flow and entities generation, during build, compilation and publishing after Entity Framework migration is being added sounds quite complicated and it is a bit. But most of it is done Source Code Generation step of compilation which is tested, reproducible process.
Rest of it is pretty much part of standard software development process – just here is done on ‘production environment’. Thing is every extension is isolated in its own schema inside the database. They never change data connected to other extensions. Unless you as an user decide to do something like that. They may relate to each other though.
After that process done you get many new endpoints, 6 for each entity in the extension. In example for API tokens:
- GET /core/apiTokens – for collection fetch operation
- GET /core/apiTokens/{id} – for single entity fetch operation
- POST /core/apiTokens – create new entity
- PUT /core/apiTokens/{id} – update entity (partial update supported)
- DELETE /core/apiTokens/{id} – delete existing entity

Not all of those endpoints are simple data manipulation. Some of them are backed by Flows on its own. For example POST /core/extensions for adding new extension is really Core extension addExtension flow. Also some endpoints are specifically for running custom flows: POST /core/extensions/fromRepository in example is used to add extension from online extensions repository.
Ok, but what is flow exactly?
Flow is a way of defining processes from existing pieces of logic, blocks. Blocks can be many things, from really simple operations like + run on numbers, so simple addition or + run on strings which is combine two strings operation, it may be a bit more complex operation like running OS executable via .NET Process API, or it may be much more complex operation like running Flow on its own as a block – sub Flow.
Blocks are defined inside the Flow library, but can be also added via extension or defined by the user dynamically. Basic blocks like SaveFileBlock (for saving a file with specific content at specific path) are already defined.
Blocks contains set of Inputs and Outputs, though not all of them at once. There may be blocks that does not output anything (i.e. DeleteDirBlock, which does not return anything) or there may be blocks that does not get any input (i.e. block that returns current date) or finally there could be blocks that does not get any input nor return any value – a bit of black box process that is identified by the name only.
Blocks can be chained together almost in anyway, given the all inputs and outputs are connected in valid way (all required inputs of all blocks are set). Generally blocks Input – Output pairs are very forgiving. For example if Output of block returns string and Input of next block takes a number Flow will try to convert output string to a number. If it will fail then flow will fail, but it will do its best first!
Flow can also have set of inputs and outputs, defined by their schemas in input.json and output.json files.
Beside IO connection blocks can be also triggered by other blocks, or specific values. I.e. if flow input object property doExtraWork
addApiToken.If(inputs.Input.CreateToken);This will cause addApiToken block to trigger only if user called first install endpoint with GET query parameter install/flow?CreateToken=true
All blocks returns also exception that happened during their execution. If those blocks are necessary by the rest of the flow pipeline it halts the entire process.
Flows can be represented by JSON file:
{
"description": "Basic Hello World flow",
"version": "1.0",
"averageTime": "00:00:01",
"triggers": {
"endpoint": {
"httpMethod": "POST",
"path": "flows/hello-world"
}
},
"blocks": [
{
"id": "helloWorld",
"comment": "Logs Hello World string",
"type": "log",
"input": {
"type": "const",
"value": "Hello World!"
}
}
]
}
This is really simple flow that represents new endpoint that is POST /flows/hello-word
[2025-09-11 13:00:14Z] || Flow: 'HelloWorldFlow' version: 1.0 [2025-09-11 13:00:14Z] LogBlock:helloWorld || Hello World!
While endpoint will return data similar to below:
POST /core/flows/hello-world
HTTP/1.1 200 OK
Content-Type: application/json; charset=utf-8
Date: Thu, 11 Sep 2025 13:00:15 GMT
Server: Kestrel
Transfer-Encoding: chunked
{
"output": null,
"scheduledId": "089b9121-26d8-4909-a119-2082f04e5a85",
"dateTime": "2025-09-11T13:00:14.7922158+00:00",
"flowName": {
"name": "HelloWorldFlow",
"extension": null
},
"userId": "019938b0-015f-7d4b-bde2-be70d16b7427",
"input": null,
"status": "success",
"progress": 0
}
So whole Flow could be represented as following diagram:
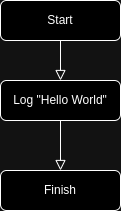
More complicated flows have much more blocks and more complex connections:
Looks much more complex and it was simplified to show in one diagram.
Ok, but looks awfully complicated!
Yes, and maybe it is. But is is also a lot of fun. And I can’t wait to implement things I planning to implement, just to see if I can do it! In example:
- Write nice FE for some tasks I do via console
- add my current IP to SSHD whitelist for few hours
- Simple blogging platform (yet another one!). WordPress is not bad but running it as separate service, that of course is often security risks with all its plugins… It is not even capable of showing SVG without plugin! With flows i.e. writing MD files, pushing them to GIT then downloading them and converting to plain HTML… it is not rocket science!
- Easily be able to log and search logs for automated administration tasks
- backups
- updates
- docker compose pulls and upgrades of stacks
- other similar custom tasks
- Have one FE to all services that do not have proper 2FA so I do not potential security issues but still have ability to do some administration stuff ‘on the run’
- Observe if server disk space is running out and notify me (other solutions, including C code or bash scripts feels really problematic in the long term; installing Nagios, Zabbix and/or Graphana, Prometheus or other combination of tools just to do that seems like overkill)
- Synchronize my ‘dot files’ (i.e. .bash_aliases across machines)
- Automating small stuff that I do very often i.e.
- generate invoice based on amount of hours I worked
- observe price of few products that I think of buying but do not need right away
- observe release notes for services I am using for potential issues
- Various notifications
- I am using emails for some and Matrix/Element for others with Apprise, but it often do not work as expected and SMTP configuration in all sources seems terrible; it would be nice to have simple way via some endpoint I can just curl to with some token
- Running some tasks via agents in small devices like routers or smartphone and observes effects in one place seems like paradise to me 🙂
All of it seems withing my grasps with this architecture. Sure there will be problems – there are always problems. But it sounds fun, a lot of experience and maybe it will be usable for other people as OSS too 🙂
Final words.
If something is complicated and will take a lot of time does it mean you not supposed to do that? I think the answer is no if this will bring you joy. After all journey is not worth taking because of destination, journey is how you will get there.