

I wrote previously why running models that you want to use on your daily driver is not great. Basically it is not convenient and it is fine for testing but if you want to run while doing something else it not great experience.
Of course you can have more powerful device so you will not notice few models running in the background but this is like running a fan with heater under your desk.
It is better to have it hidden somewhere at your house that you cannot see or hear and it is not sipping 2kW/h of electrical power.
Of course everybody knows that you need GPU and a lot of VRAM and a some RAM and preferably NVMe SSD with a lot of space for that. This is why prices of those components are very high. And are getting pricier. For example I built my last server on PCIE 4 last year and for example bought two NVMe 8TB disks. They costed me around 600$. Now one costs around 1200$. Things are crazy.
GPUs are most problematic now though.
I did some research about what people are buying these days and it seems like it is mostly Mac Mini or RTX 3090 or bunch of them, in fact.
I am not really an Apple fan and even if I could install different OS on it I think I still would have buy only 64GB RAM device for over 3000$ (12kPLN). Not great. I though I could do better.
There is also possibility of buying Mac Studio. But the price of that is crazy. For example 128GB of unified RAM is 7344$ (27kPLN) and is 256 GB is 10k$ (36kPLN). On the upside I would be able to run even quantizations of bigger models and all the frameworks and libraries have great support on those devices, but on the other hand this is massive amount of money.
There is possibility of buying GPU multiple GPUs. But, again this is very pricey. Nvidia RTX 5090 price after all this years is still huge. And it is just one card with 32GB of RAM. To run 2 models at the same time I would need at least two. And it still would be just 64GB. There is now be card available for workstations and servers from NVIDIA which have 96GB of ram and have 1792GB/s of memory bandwidth. This looks sweet… But it costs 8-16k$ (36-60kPLN). This is… No just no.
There are also AMD cards. Previously they were not worth the trouble. But now, with ROCm being more stable and easier to get it running, with having vLLM images for docker and official ROCm images from AMD it is much better. You can have running your favorite model on your Radeon in few minutes. Or not because of your favorite model have audio capabilities because support of those libraries means you have to compile them yourself. Still this seems like good choice. I.e. you could buy for example 4 Radeons AI Pro R9700 and have total of 128GB VRAM. Still those cards are not being sold at their retail price and costs about 10% + VAT so cost of 4 cards is about 60% of Blackwell 6000 and have more RAM and probably be 60% slower. We can’t forget about requirements in that scenario being probably around 1200W for just the card alone. Squeezing any 4 cards in any case it the problem here too. And of course cooling of such monster…
Of course there are dedicated solutions for those problems too! You can really connect as many cards as you need with solutions like this one and power them with something like that.


But when you do custom things like that then when you have a problem you hardly can ask someone for help. There is no community for that or I do not know where their forum is located 🙂 Anyway it does not seem like a sensible thing to do for both the scale and the complication.
And there is new APU from AMD that seemed like really good idea. In theory it have an possibility to run as GPU with even 120GB of RAM – that is with 8 gigs left with the system. But the GPU performance is not that great:

- and about the level of performance of GeForce RTX 4070
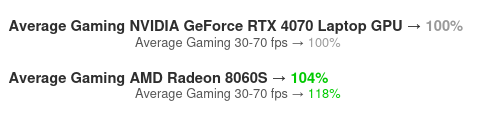
But you can ran bigger models, though it will be a bit slow, but bearable.
Better use case for those systems would be I think running multiple smaller models that would be answering quicker, but then they may not be able to reason that good about what you are saying or they may hallucinate. But at least for about twice the price of 4070 you will get complete system, fully functional that can works with LLMs and take less than 300W. That is pretty good.
And there is possibility of building clusters of devices.
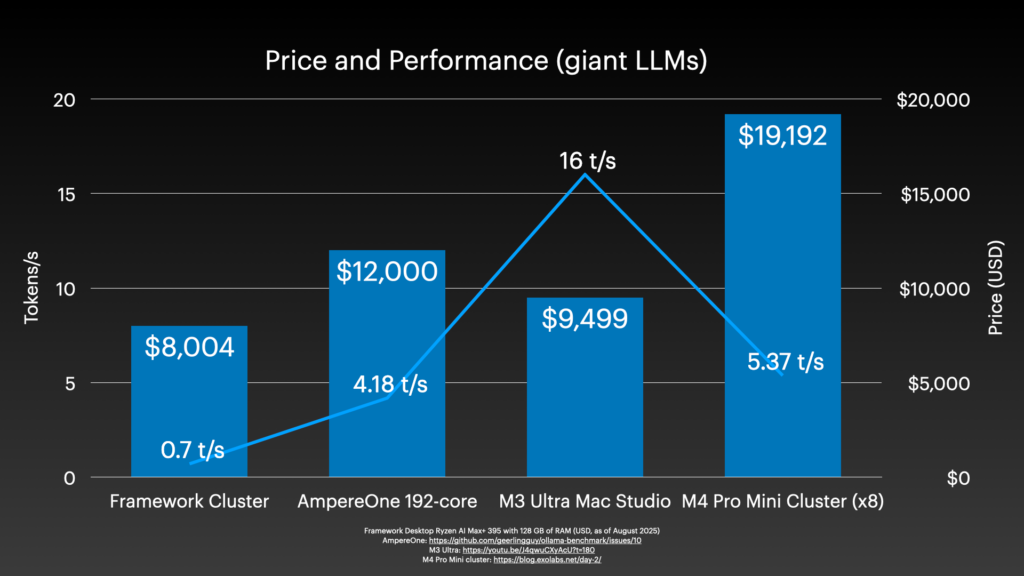
Honestly spending 20k$ on hardware to build cluster and get less than 6 tokens per second? You can also burn your money. Maybe for training this setup would make sense but not for inference.
So what to do?
Basically there is no winning scenario in this.
- Either run really small models or reaaaaaaaly slowly bigger models on CPU
- Or you spend less money and have slow device with unified memory and run models from bigger set of available to your RAM (like amd ryzen ai max+ 395)
- Or you spend less money and have slow device with unified memory and have better support of framework and libraries
- Or you spend less money on some mid range GPU, possibly used and run some smaller models fast (like GeForce 3090)
- Or buy few cards like that used 3090 and connect them somehow with bifurcation to one motherboard and pray to not go bankrupt after electricity bill will come
- Or if you not concerned about money buy bigger device with unified memory (Mac Studio) so you will be able to run large set of models on any framework
- Or if you really have to much money just buy four server grade Nvidia cards and burn through electricity and your wallet running giant models really fast
- Or… forget about running it on your own and just buy some subscription or rent a server! This is pretty cost effective since it is not you will be burning through your credits for tokens adding groceries to your TODO list
Thinking about that I realized that last thing would be most reasonable thing to do. But this is not about that. I like my privacy. That is why I have my own e-mail server. That is why I have my own cloud solution. That is why I have de googled my phones. That is why I do not have Windows. I do not plan to sell my data just to have some bot send me summarization of my own calendar that I have self hosted too. This is why I did next not-so-bad thing and decided to buy Strix Halo machine, PC based on AMD Ryzen AI Max+ 395. With Linux installed, unified memory configured mostly for GPU that is a bit slow but should still give me decent interference speed.
Prices of those machines are not great too but at least they should be power effective. I considered:
- GMKTEC EVO-X2 which is a bit pricey being around 15kPLN (~4kUSD) and people were complaining about some problems with it
- There is also Framework Desktop that is priced a bit better and Framework seems like a bit more trusting brand. And this unit looks pretty slick. Too bad it also have only lousy 2,5GB/s network
- There is Beelink GTR9 Pro which looks really nice with 10GB/s and USB4… But it can be only pre-ordered and you have to wait for 35 days
- And there is Minisforum MS-S1 MAX which looks like the best option there with better price and double 10GB/s NIC and USB-4. And price is 135000PLN (~3672USD)
Minisforum seemed like a best option really. I would have to wait few days though for it. Desktop from the Framework was available right away and… I could buy only the motherboard. Design is nice but they ask you to buy pieces of plastic for few dollars each.

I could print them myself though. Or not buy them. I decided on the latter and just bought the motherboard.
With the predicted delivery in 3 working days and total price of 8,804.06 (~2400USD) it looked fairly sensible solution.
I ordered one and it will arrive on Wednesday! Can’t wait!
2 Replies to “Self hosting your AI assistant efficiently”